I’m training to run a marathon (Run Rootie!) and basing my training plan on the Chris Evans book “119 days to go”. That training plan is based around time you spend running rather than distance to run each time.
I like the approach but it’s made it really hard for me to plan my running routes. Now I know that I’m running around 7 minutes per km I wanted to convert every run duration into distance and add it to my calendar.
To do that, I made a spreadsheet with a few formulas, then exported a CSV file in a format calendars like, import it into my google calendar, and quicker than Steve can run a marathon I now have every training run suggested time and distance in my calendar
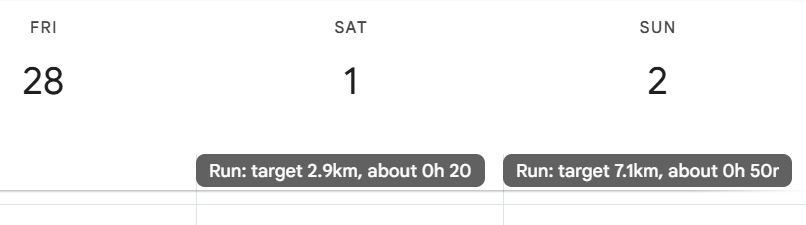
If you’re doing the same thing, here’s my spreadsheet you can download an change to suit your own marathon date. It’s a ODS file (which is Open Document Spreadsheet format) that will open in Excel and many other spreadsheet applications.

